Databases & Resources for Proteome-Level PTM Information
Databases and resources for proteome-level PTM information
A foundation of our work is the ability to have proteome information at our fingertips. This includes the current knowledge of tyrosine phosphorylation, quantitative measurements measured on those sites, and related protein annotations. In enabling this research for our own lab, we also construct tools that can be used by the broader research community, with a focus on extendibility and reproducibility.
ProteomeScout
ProteomeScout is our database of post-translational modifications and their protein annotations. The major features of ProteomeScout include:
- Deposition of experimental data. The current standard of publishing static files regarding PTM-measurements is a serious problem in quantitative proteomics. Database records quickly change and it becomes difficult to map older experiments to new databases. ProteomeScout serves as a living repository of this information.
- Exploration and analysis of experimental data. ProteomeScout includes flexible interfaces to explore datasets, including automatic enrichment testing. This framework can be interfaced to MCAM (our ENSEMBLE CLUSTERING framework).
- Up-to-date protein and PTM information from both databases and primary experiments.
- Database download. The database can be downloaded in flat-text files and is updated weekly, with stable releases every six months. This avoids the hassle of having to hand-wrangle multiple resources when one would like to perform a proteome-level PTM computational exploration.
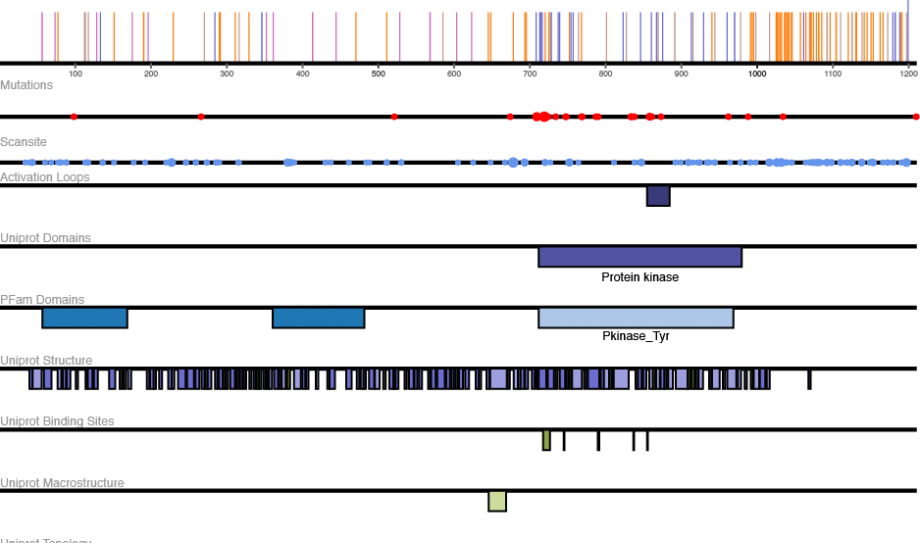
- Protein viewer. Inspired by the UCSC genome browser, we built a protein browser that allows you to visualize protein feature elements in relation to each other (for example, PTMs relative to mutations and protein domains). These tracks can be manipulated for size and features and exported for insertion into web pages, grants, articles, etc.
ProteomeScoutAPI
The ProteomeScoutAPI is a Python library that allows you to easily interact with the entire database download of ProteomeScout. Building proteome-level analysis with the ProteomeScout database and the API means that re-analysis of future data is as easy as re-running your code with a new file download. We demonstrated this in our PROTEOMESCOUTAPI PAPER, where we tested the hypothesis that missense mutations near sites of modifications are more likely to be related disease since they may have a functional consequence in altering the regulation or recognition of a modification. This paper also includes historical data that demonstrates that the speed of discovery requires flexible tools for analysis of the proteome as the results are changing significantly between the time of the results and the publication of a paper (let alone years after the study).
A foundation of our work is the ability to have proteome information at our fingertips.